认识递归
定义
程序调用自身的编程技巧称为递归( recursion)。递归做为一种算法在程序设计语言中广泛应用。一个过程或函数在其定义或说明中有直接或间接调用自身的一种方法,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,递归策略只需少量的程序就可描述出解题过程所需要的多次重复计算,大大地减少了程序的代码量。递归的能力在于用有限的语句来定义对象的无限集合。一般来说,递归需要有边界条件、递归前进段和递归返回段。当边界条件不满足时,递归前进;当边界条件满足时,递归返回。
概括来讲就是函数直接或间接的调用自身的编程方式称为递归;同时递归的构成需要有边界条件、递归前进段和递归返回段。
~ 下面来一步一步的探索递归函数
步骤一
- 根据定义创建一个简单的递归函数控制台输出:
1
2
3
4
5
6
7
8function a(n) {
if ( n > 0 ) {
a( n - 1 )
} else {
return n
}
}
a(3)undefined;在合适的条件下终止了递归,完美退出没有造成死循环。:-)
步骤二
- 查看递归函数内值的变化控制台输出:
1
2
3
4
5
6
7
8
9
10
11function a(n) {
console.log('头部输出:' + n )
if ( n > 0 ) {
a( n - 1 )
} else {
console.log('递归终止时输出:' + n)
return n
}
console.log('尾部输出:' + n )
}
a(3)
直观认为数值应该是交替输出的,但真实输出结果却是个有趣的现象,这似乎要说明什么问题了;从现象本身看输出结果是一个入栈和出栈的过程,以递归调用为分界线,分界线以上的内容先输出,分界线以下的后输出;‘头部输出’可以理解为函数的调用次序,‘尾部输出’可以理解为函数的求值(返回值)顺序,整个过程就是从上到下逐层的调用,然后值又由从下到上的返回。头部输出:3 头部输出:2 头部输出:1 头部输出:0 递归终止时输出:0 尾部输出:1 尾部输出:2 尾部输出:3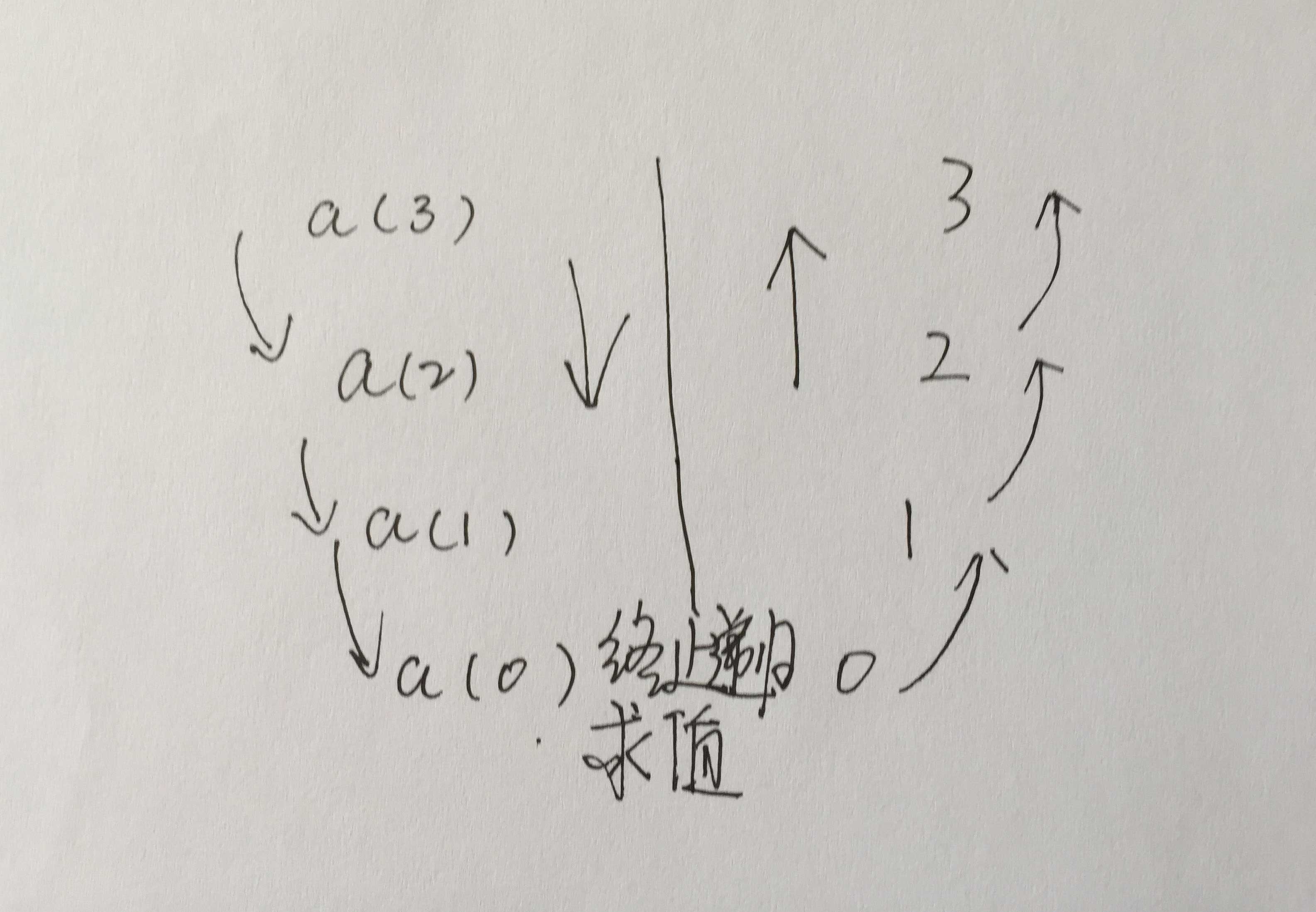
步骤三
查看函数调用返回值
1
2
3
4
5
6
7
8
9function a(n) {
if ( n > 0 ) {
a( n - 1 )
} else {
return n
}
return n
}
a(3)控制台输出:
3,由Step2的分析不难得到这个结果,好像和有咩有递归没什么区别,只能说明这么做没有什么意义。:-)获取递归最内层值
1
2
3
4
5
6
7
8function a(n) {
if ( n > 0 ) {
return a( n - 1 )
} else {
return n
}
}
a(3)控制台输出:
0,最内层值层层往上抛,最外层的调用就得到了最内层的值。来点有趣的把值的变化串起来
1
2
3
4
5
6
7
8function a(n) {
if ( n > 0 ) {
return a( n - 1 ) + ' ' + n
} else {
return n
}
}
a(10)控制台输出:
"0 1 2 3 4 5 6 7 8 9 10"虽然上述的代码没有什么重大意义,但也展示递归的基本使用方式。
尾递归
如果一个函数中所有递归形式的调用都出现在函数的末尾,我们称这个递归函数是尾递归的。当递归调用是整个函数体中最后执行的语句且它的返回值不属于表达式的一部分时,这个递归调用就是尾递归。尾递归函数的特点是在回归过程中不用做任何操作,这个特性很重要,因为大多数现代的编译器会利用这种特点自动生成优化的代码。
当编译器检测到一个函数调用是尾递归的时候,它就覆盖当前的活动记录而不是在栈中去创建一个新的。编译器可以做到这点,因为递归调用是当前活跃期内最后一条待执行的语句,于是当这个调用返回时栈帧中并没有其他事情可做,因此也就没有保存栈帧的必要了。通过覆盖当前的栈帧而不是在其之上重新添加一个,这样所使用的栈空间就大大缩减了,这使得实际的运行效率会变得更高。虽然编译器能够优化尾递归造成的栈溢出问题,但是在编程中,我们还是应该尽量避免尾递归的出现,因为所有的尾递归都是可以用简单的goto循环替代的。
意思就是编译器对尾递归做了特殊处理,可能在性能上或许有所提升。
总结
函数递归的整个过程就是从上到下逐层的调用,然后求值又由从下到上的返回;以递归调用为分界线,分界线以上的内容先输出,分界线以下的后输出。